数据结构学习笔记之串结构
本文共 7405 字,大约阅读时间需要 24 分钟。
串
一、串的基本概念
1、串的定义
串,String,是由零个或多个字符组成的有限序列,一般记为:S=‘abcd……’,其中S称为串名,单引号括起来的字符序列就是串的值,序列中的元素可以是字母、数字或其他可打印字符,元素个数 n 称为串的长度,当且仅当 n=0 时字符串才是空串。若字符序列是由若干空格构成,称为空格串,其长度 n 为空格个数。- 串占据的存储空间为 n+1,因为每个串都有一个结束标记,一般是
\0。
2、串的存储结构
- 串的存储结构有三种:
顺序存储、堆存储和块链存储。
2.1、顺序存储
- 顺序存储就是用一组连续的存储单元存储串值,一般是用方括号声明字符数组来刻画;采用顺序存储结构表示的串,一般是定长的,每个串变量都有一个固定长度的存储区,而串变量的字符序列的元素个数必须小于这个固定长度,否则就会产生截断——超过定义长度的值全被舍去。
2.2、堆分配存储
- 指的是字符数组,不使用“a[len]" 形式声明为字符数组,而是采用指针声明,在程序执行过程中动态分配存储空间。
- 采用堆分配存储结构的串,串变量之间所占据的存储区可以不等长,这种形式相对符合实际情况的需要。
2.3、块链存储表示
- 即采用链式存储结构存储值,每个结点可以只存储一个字符,也可以存储多个字符。每个结点称为
块,整个链表称为块链结构,如下图:
3、串的基本操作
串结构的基本操作如下:
- StrAssign(&T, chars):赋值操作,将 chars 赋值给 T。
- StrCopy(&T,S):复制操作,将 S 复制到 T 中。
- StrEmpty(S):串判空操作。
- StrCompare(S, T):串比较操作,从第一个字符开始比较,若第一个字符相等才比较第二个……依次类推。
- StrLength(S):获取串长度。
- Concat(&T, S1,S2):合并串,将 S2 衔接在 S1 尾部并赋值给 T。
- SubString(&sub, S, pos, len):求子串,用 Sub 返回 S 串中第 pos 个字符起长度为 len 的子串。
- Index(S, T, pos):定位操作,判断 T 是否出现于 S 中,若有则返回S第一次出现的位置,反之则返回 -1.
- ClearString(&S):清空串,将 S 清为空串。
- DestroyString(&S):销毁串。
二、串结构自定义实现
- 采用堆分配存储结构,编程语言采用 C++。
#pragma once#include
#include using namespace std;class HeapStr{ private: char* data; int length;public: HeapStr(); bool StrAssign(string s); void Show(); void StrCopy(HeapStr s); bool StrEmpty(); int StrCompare(HeapStr s); int StrLength(); void SubStr(HeapStr& sub, int pos, int len); void Concat(HeapStr s1, HeapStr s2); int Index(HeapStr sub); bool ClearStr();};// 构造串HeapStr::HeapStr(){ data = NULL; length = 0;}bool HeapStr::StrAssign(string s){ int len = s.length(); try { data = (char*)malloc((len + 1) * sizeof(char)); for (int i = 0; i < len; i++) data[i] = s[i]; data[len] = '\0'; length = len; return true; } catch (exception e) { cout << e.what() << endl; return false; }}// 判空bool HeapStr::StrEmpty(){ if (data == NULL) { cout << "未初始化赋值" << endl; return true; } if (length == 0) return true; return false;}int HeapStr::StrLength(){ if (data == NULL) { cout << "未初始化赋值" << endl; return -1; } else if (this->StrEmpty()) { cout << "串空!" << endl; return 0; } return length;}void HeapStr::Show(){ if (data == NULL) { cout << "未初始化赋值" << endl; return; } else if (this->StrEmpty() || data[0] == '\0') { cout << "串空!" << endl; exit(0); } cout << data << endl;}void HeapStr::StrCopy(HeapStr s){ if (s.length == 0) { cout << "参数为空串!" << endl; return; } if (s.data == NULL) { cout << "参数错误,未初始化赋值" << endl; exit(0); } int len = s.length; if (this->length < len) { cout << "参数串太长,将发生截断" << endl; for (int i = 0; i < length; i++) data[i] = s.data[i]; data[length] = '\0'; } for (int i = 0; i < len; i++) data[i] = s.data[i]; data[len] = '\0';}int HeapStr::StrCompare(HeapStr s){ if (data == NULL && s.data == NULL) { cout << "未初始赋值!" << endl; exit(0); } if (this->StrEmpty() == s.StrEmpty()) return 0; int i; if (length < s.length) { for (i = 0; i < length; i++) { if (data[i] > s.data[i]) return 1; else if (data[i] < s.data[i]) return -1; } if (i == length) return 0; } for (i = 0; i < s.length; i++) { if (data[i] > s.data[i]) return 1; else if (data[i] < s.data[i]) return -1; } if (i == s.length) return 0;}void HeapStr::SubStr(HeapStr& s, int pos, int len){ if (data == NULL) { cout << "未初始化赋值" << endl; return; } else if (this->StrEmpty()) { cout << "串空!" << endl; return; } for (int i = 0; i < len; i++) { s.data[i] = data[i + pos - 1]; } s.data[len] = '\0';}void HeapStr::Concat(HeapStr s1, HeapStr s2){ if (data == NULL) { cout << "未初始化赋值" << endl; return; } for (int i = 0; i < s1.length; i++) data[i] = s1.data[i]; for (int j = 0; j < s2.length; j++) data[j + s1.length] = s2.data[j]; data[s1.length + s2.length - 1] = '\0';}int HeapStr::Index(HeapStr sub){ if (sub.length > length) return -1; int i = 0, j = 0; while (i < length && j < sub.length) { if (data[i] == sub.data[j]) { ++i; ++j; } else { i = i - j + 2; j = 0; } } if (j > sub.length) return i - sub.length; else return 0;}bool HeapStr::ClearStr(){ if (data == NULL) { cout << "串未初始化赋值" << endl; exit(0); } if (length == 0) { return true; } data[0] = '\0'; length = 0; return true;}
三、串的模式匹配算法
- 所谓模式匹配,指的是
查找较短的一个串在较长的一个串中第一次出现的位置,简单来说就是确定子串在母串中的位置,子串通常称为模式串,母串则称主串。 - 串的模式匹配算法,有
暴力算法、KMP 算法和改进的 KMP 算法。
1、暴力匹配
- 所谓暴力匹配就是不采用任何技巧,母串从头开始于子串的每个字符注意比较,若相等则母串和子串同时后移一个字符;若不等,母串后移一个字符,子串从新第一个字符开始。暴力匹配算法实现比较简单,但时间复杂度大,为
O(mn);一旦遇到母串和子串都比较长,那么时间就需要很久了。 - 暴力匹配算法实现代码如下:
int HeapStr::Index(HeapStr sub){ if (sub.length > length) return -1; int i = 0, j = 0; while (i < length && j < sub.length) { if (data[i] == sub.data[j]) { ++i; ++j; } else { i = i - j + 2; j = 0; } } if (j > sub.length) return i - sub.length; else return 0;}
2、KMP 匹配算法
- 在暴力匹配中,每次匹配失败都是模式后移一位再从头开始比较。而某次已匹配相等的字符序列是模式的某个前缀,这种频繁的重复比较相当于模式串在不断地进行自我比较,这就是其低效率的根源。
如果已匹配相等的前缀序列中有某个后缀正好是模式的前缀,那么就可以将模式向后滑动到与这些相等字符对齐的位置,主串立指针无须回溯,并继续从该位置开始进行比较。而模式向后滑动位数的计算仅与模式本身的结构有关,与主串无关。
2.1、前缀、后缀与部分匹配值
- 1)前缀:
除最后一个字符外,字符串的所有头部子串。 - 2)后缀:
除第一个字符外,字符串的所有尾部子串。 - 3)部分匹配值:
字符串的前缀和后缀的最长相等前后缀长度,通俗理解就是前缀集与后缀集的交集中的长度最长的元素的字符个数。 - 举例如下:
'ab' 的前缀为{a},后缀为{b},前缀集与后缀集交集为空集,最长相等前后缀就是 0.'aba' 的前缀为{a,ab},后缀为{a,ba},两者交集为{a},最长相等前后缀就是 1.'ababa'的前缀为{a,ab,aba,abab},后缀{a,ba,aba,baba},两者交集为{a,aba},最长相等前后缀为 3
2.2、部分匹配值的作用
- 部分匹配值用于确定匹配过程中出现某一字符不匹配时,子串沿母串向后移动的位数:
移动位数=已匹配的字符数 - 对应的部分匹配值。- 以 母串为:
ababcabcacbab,和模式串:abcac为例。
- 首先模式串的部分匹配值(Partial Match,PM)表如下:(00010),可以理解为某个字符在之前序列中的出现次数。
- 因此第一趟匹配失败后,模式串沿母串向后移动了 2- 0= 2
- 第二趟匹配失败,向后移动 4 - 1 = 3
- 第三趟成功。
2.3、next 数组
- 若令 next[j] = k,则
next[j] 表明当模式中第 j 个字符与主串中相应字符不相等时,在模式中需要重新和主串中该字符进行比较的字符的位置。 - next 函数定义如下:

- 首先由公式可知,next[1]=0
- 假设 next[j] = k,k 的条件如公式所示。
- 则 next[j+1] = ? 1)若 pk=pj,则模式串中有:p1…pk-1pk = pj-k+1…pj-1pj,此时 next[j+1]=k+1,即 next[j+1] = next[j] + 1 2)pk!=pj,则说明模式串中:p1…pk-1pk != pj-k+1…pj-1pj,

- 以下面的模式串为例:
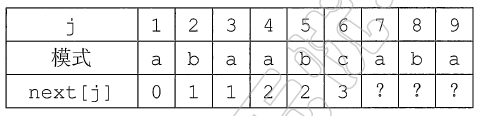
- 根据规则,首先令 next[1] = 0,当 j=2 时,因为不存在相同子串,取 k=1,即next[2]=1;当 j=3 时,因为 j=2 时 pk=a != pj=b,且 j !=1,所以 k=1;当 j=4 时,因为 p1=p3,所以p4=p3+1=2;当 j=5 时,由于 p2!=p4,根据规则 1<k<5,取 k=2,3,4,当k=2 时,p1=p4,k=3 时 p1p2 != p3p4,k=4 时,p1p2p3 != p2p3p4,因此 k=2;当 j=6 时,p5=p2,所以 p6=p5+1=3;j=7 时,p6!=p3 且找不到长度更短的相等前缀后缀,取k=1,接下来又是和前面一样。
- 得出完整的 next 数组如下:
j 1 2 3 4 5 6 7 8 9 模式 a b a a b c a b a next[j] 0 1 1 2 2 3 1 2 3
2.4、算法实现
- KMP 算法结合 next 数组可以高效的进行模式串匹配,相关代码如下:
// 模式匹配 KMP 算法int HeapStr::IndexKMP(HeapStr sub){ int len = sub.length; int* next = new int[len + 1]; for (int k = 0; k <= len; k++) { next[k] = 0; } int i = 1, j = 0; while (i < len) { if (j == 0 || sub.data[i] == sub.data[j]) { ++i; ++j; next[i] = j; } else j = next[j]; } i = 1, j = 1; while (i <= this->length && j <= sub.length) { if (j == 0) { ++i; ++j; } else if (j != 0 && this->data[i - 1] == sub.data[j - 1]) { ++i; ++j; } else j = next[j]; } if (j > sub.length) return i - sub.length; else return -1;} - 时间复杂度时 O(n+m),相比暴力匹配算法的 O(nm) 好很多了,不过值得注意的是,
KMP 算法仅在主串与子串有很多部分匹配时才显得比普通算法快很多,其主要优点是主串不回溯。
3、改进的 KMP 算法
- 上面的 KMP 算法中求
next得算法尚有缺陷,尤其是处理 pj!=pk 时,第 k 个字符得 next[j] 所在的字符与pk 一样因而也不等于 pj,此时显然需要进行递归,即将 next[j] 改为 next[next[j]] ,直到两个不相等为止,为了与原来的算法区别,此时用于确定模式串滑动位置的数组命名为nextval。 - 关键代码如下:
while (i < len) { if (j == 0 || sub.data[i] == sub.data[j]) { ++i; ++j; if (sub.data[i] != sub.data[j]) nextval[i] = j; else nextval[i] = nextval[j]; } else j = nextval[j]; } 转载地址:http://mqqgn.baihongyu.com/
你可能感兴趣的文章
Java传统IO / NIO基础知识
查看>>
Netty3- 入门示例
查看>>
Netty3 - 多连接的客户端示例
查看>>
Netty3 -会话状态监听
查看>>
Netty3 - 对象的序列化与反序列化ProtoBuf
查看>>
Netty3 - 对象的序列化与反序列化 java
查看>>
Netty3 - 自定义序列化协议(1)
查看>>
Netty3 - 自定义序列化协议(2)
查看>>
数据缓存一致性方案
查看>>
分布式锁原理 --及常见实现方式的优劣势分析
查看>>
一:Lua 数据类型及表达示
查看>>
二:Lua 基本语法
查看>>
Ubuntu 18.04 界面美化之windows任务栏
查看>>
QT 5.9.0 移植
查看>>
objdump 反汇编 vmlinux详解
查看>>
sudo命令无法读取环境变量的解决方法
查看>>
Qt中configure参数配置说明
查看>>
Ubuntu 添加右键打开终端
查看>>
Linux 内核开机logo制作
查看>>
WIN10 + Ubuntu 16.04 双系统安装教程
查看>>